


 ChatGPT, Claude, Gemini, Grok, Copilot yahut öteki lisan modellerini (LLM) temel alan tüm yapay zekalar dünyanın büyük bir kısmı için sihir üzere görünen fonksiyonlara sahip. İşin biraz daha mutfağına hakim olanlar için ise bu araçlar, olağanüstü bir yardımcı. İşin şahsen içinde olanlar için ise bunlar aslında bir kara kutu. Zira aslında bilim insanları ve araştırmacılar, bir lisan modelinin tam olarak nasıl çalıştığını bilmiyor. Lakin Claude’un yaratıcısı Anthropic‘teki araştırmacılar, bu mevzuda önemli bir atılım yaptıklarını söylüyor. Bu keşif, yapay zeka modellerini daha inançlı, şeffaf ve muteber hale getirme yolunda kritik bir adım olarak bedellendiriliyor.
ChatGPT, Claude, Gemini, Grok, Copilot yahut öteki lisan modellerini (LLM) temel alan tüm yapay zekalar dünyanın büyük bir kısmı için sihir üzere görünen fonksiyonlara sahip. İşin biraz daha mutfağına hakim olanlar için ise bu araçlar, olağanüstü bir yardımcı. İşin şahsen içinde olanlar için ise bunlar aslında bir kara kutu. Zira aslında bilim insanları ve araştırmacılar, bir lisan modelinin tam olarak nasıl çalıştığını bilmiyor. Lakin Claude’un yaratıcısı Anthropic‘teki araştırmacılar, bu mevzuda önemli bir atılım yaptıklarını söylüyor. Bu keşif, yapay zeka modellerini daha inançlı, şeffaf ve muteber hale getirme yolunda kritik bir adım olarak bedellendiriliyor. Yapay zekanın anlaşılamayan dünyası
Günümüzde yapay zekanın temelini oluşturan büyük lisan modelleri, insan lisanını anlamak ve üretmekte harika bir muvaffakiyet gösterse de, bu modellerin karar verme süreçleri büyük ölçüde gizemini koruyor. Bir modele hangi komutların verildiğini ve ne çeşit karşılıklar ürettiğini görebiliyoruz; lakin bu cevapların nasıl oluşturulduğunu anlamak hala belirsizliğini koruyor.
Bu bilinmezlik, yapay zeka uygulamalarında inanç meselelerine yol açıyor. Modellerin, kusurlu bilgiler üretme (halüsinasyon) eğilimlerini evvelce kestirim etmek zorlaşıyor. Ayrıyeten, birtakım kullanıcılar tarafından modellerin güvenlik tedbirlerini aşmak için uygulanan “jailbreak” tekniklerinin neden birtakım durumlarda işe yaradığı hala tam olarak açıklanamıyor.
Anthropic araştırmacıları, bu karmaşık yapıyı çözümlemek için büyük bir adım attı. İnsan beynini incelemek için kullanılan fMRI teknolojisinden ilham alan takım, büyük lisan modellerinin iç işleyişini anlamaya yönelik yeni bir araç geliştirdi. Bu teknik, yapay zeka modellerinin “beyinlerini” haritalandırarak hangi süreçlerin devreye girdiğini ortaya koyuyor.
Bu yeni aracı Claude 3.5 Haiku modeline uygulayan araştırmacılar, yapay zekanın şuurlu olmasa bile planlama ve mantıksal çıkarım yapabildiğini gösterdi. Örneğin, bir şiir yazma misyonu verildiğinde modelin, uyumlu sözleri evvelce belirleyip akabinde bu sözlere uygun cümleler kurduğu gözlemlendi.
Araştırmanın bir öteki dikkat cazip bulgusu ise lisan modellerinin çok lisanlı çalışmasındaki mantık yapısı oldu. Claude modeli, farklı lisanlarda farklı bileşenler kullanmak yerine, tüm lisanlar için ortak kavramsal bir alan kullanarak çalışıyor. Yani model, evvel soyut kavramlar üzerinden bir akıl yürütme sürecine giriyor ve akabinde bu kanıyı istenilen lisana çeviriyor.
Bu bulgu, çok lisanlı yapay zekaların nasıl daha verimli hale getirilebileceğine dair yeni kapılar aralıyor. Bilhassa global ölçekli yapay zeka tahlilleri geliştiren şirketler için bu yaklaşım, modellerin daha dengeli ve süratli çalışmasını sağlayabilir.
Kara kutunun açılması neden değerli?
 Anthropic’in geliştirdiği yeni tahlil aracı, yapay zekaların karar verme süreçlerini izleyerek muhtemel güvenlik açıklarını daha âlâ tespit etmeye yardımcı olabilir. Bu yeni yol, yapay zekaların “kara kutu” olma meselesine tahlil getirme potansiyeline sahip. LLM’lerin hangi adımları takip ederek muhakkak bir karşılık oluşturduğunu anlamak, bu modellerin neden yanılgı yaptığını tahlil etmeyi kolaylaştırabilir. Ayrıyeten, yapay zeka sistemlerinde güvenlik tedbirlerini güçlendirmek ve yanlışlı yahut aldatıcı çıktıları azaltmak için daha tesirli eğitim yolları geliştirmenin önünü açabilir.
Anthropic’in geliştirdiği yeni tahlil aracı, yapay zekaların karar verme süreçlerini izleyerek muhtemel güvenlik açıklarını daha âlâ tespit etmeye yardımcı olabilir. Bu yeni yol, yapay zekaların “kara kutu” olma meselesine tahlil getirme potansiyeline sahip. LLM’lerin hangi adımları takip ederek muhakkak bir karşılık oluşturduğunu anlamak, bu modellerin neden yanılgı yaptığını tahlil etmeyi kolaylaştırabilir. Ayrıyeten, yapay zeka sistemlerinde güvenlik tedbirlerini güçlendirmek ve yanlışlı yahut aldatıcı çıktıları azaltmak için daha tesirli eğitim yolları geliştirmenin önünü açabilir. Öte yandan bazı uzmanlar göre LLM’lerin bu gizemli yapısı çok da büyük bir problem değil.
 Beşerler olarak bir oburunun ne düşündüğünü hakikaten anlayamayız ve aslında psikologlar bazen kendi niyetlerimizin nasıl çalıştığını bile anlamadığımızı, sezgisel olarak ya da büyük ölçüde şuurunda bile olmadığımız duygusal reaksiyonlar nedeniyle yaptığımız hareketleri haklı çıkarmak için olaydan sonra mantıklı açıklamalar uydurduğumuzu söylüyor. Fakat, genel manada insanların benzeri hallerde düşünme eğiliminde olduğu ve yanılgı yaptığımızda bu yanlışların bir halde tanıdık kalıplara girdiği de hakikat görünmekte. Esasen psikologların işlerinde âlâ olmasının nedeni de bu.
Beşerler olarak bir oburunun ne düşündüğünü hakikaten anlayamayız ve aslında psikologlar bazen kendi niyetlerimizin nasıl çalıştığını bile anlamadığımızı, sezgisel olarak ya da büyük ölçüde şuurunda bile olmadığımız duygusal reaksiyonlar nedeniyle yaptığımız hareketleri haklı çıkarmak için olaydan sonra mantıklı açıklamalar uydurduğumuzu söylüyor. Fakat, genel manada insanların benzeri hallerde düşünme eğiliminde olduğu ve yanılgı yaptığımızda bu yanlışların bir halde tanıdık kalıplara girdiği de hakikat görünmekte. Esasen psikologların işlerinde âlâ olmasının nedeni de bu. Bununla birlikte büyük lisan modelleri (LLM’ler) ile ilgili sorun, çıktılara ulaşma usullerinin insanların birebir vazifeleri yapma biçiminden hayli farklı olması. Bu nedenle, bir insanın yapması pek muhtemel olmayan yanılgılar yapabilirler.
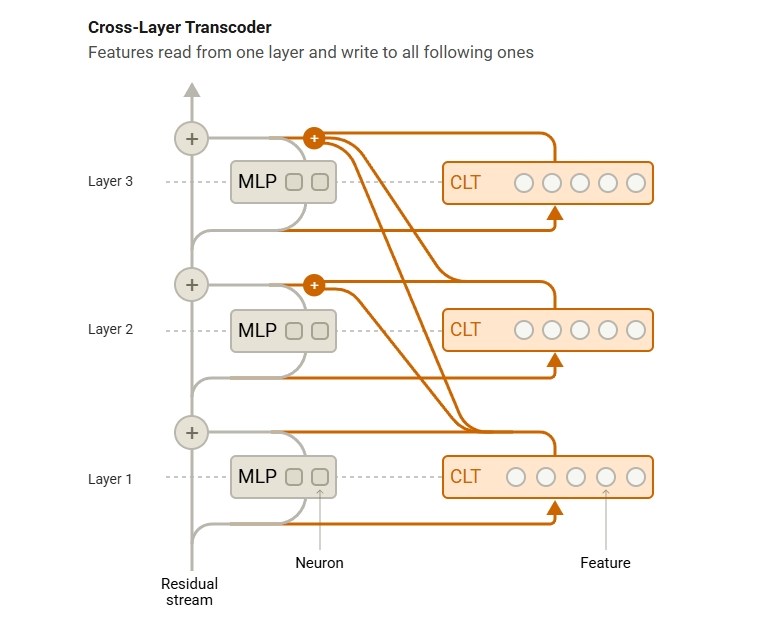
Cross-Layer Transcoder (CLT) yaklaşımı
 Daha evvelki LLM tahlil metotları, tek tek nöronları yahut küçük nöron kümelerini incelemek üzerine heyetiydi. Alternatif olarak, modelin kimi katmanlarını çıkartarak nasıl çalıştığını gözlemlemeye dayalı “ablasyon” tekniği de kullanılıyordu. Lakin bu sistemler, modelin genel düşünme sürecini anlamak için yetersiz kalıyordu.
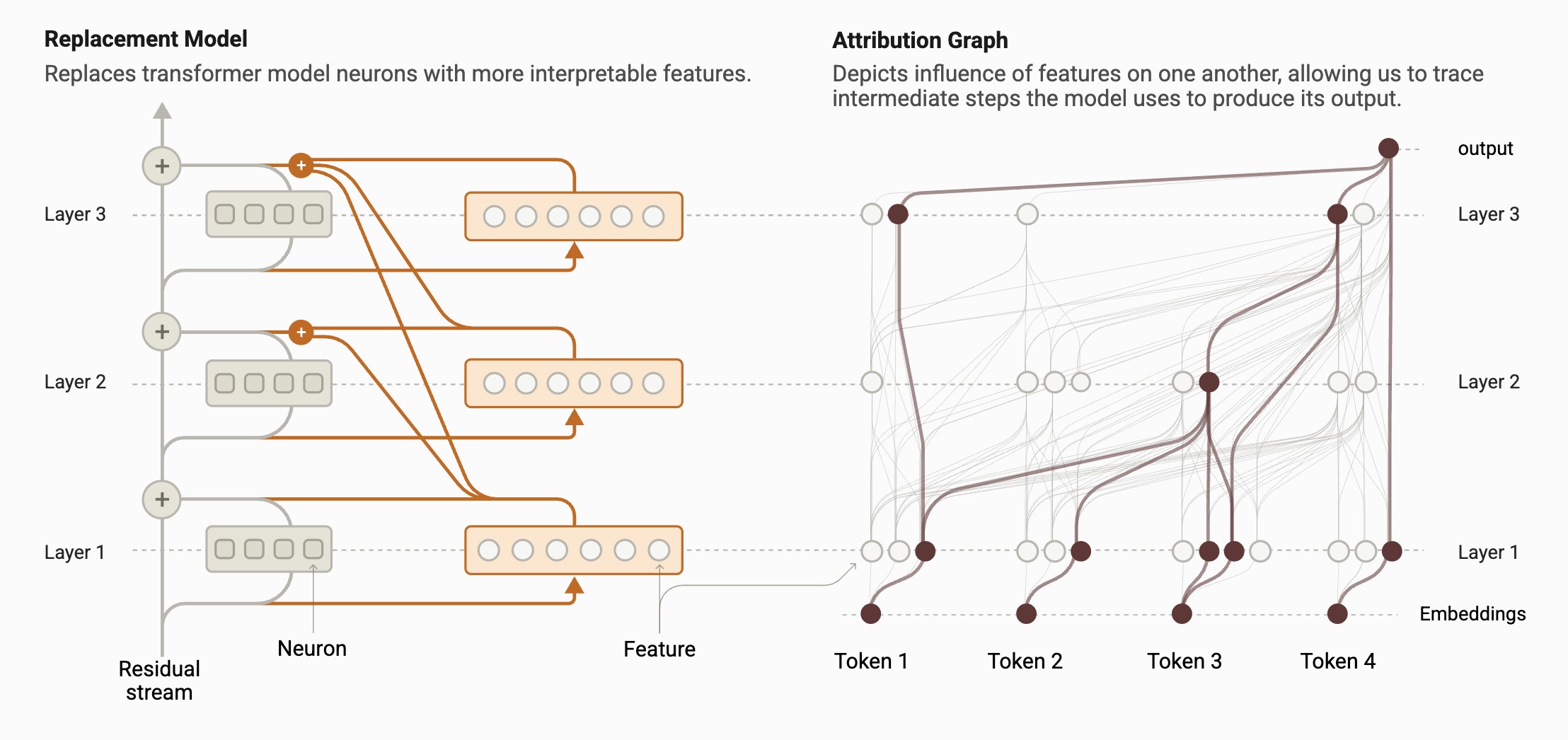
Daha evvelki LLM tahlil metotları, tek tek nöronları yahut küçük nöron kümelerini incelemek üzerine heyetiydi. Alternatif olarak, modelin kimi katmanlarını çıkartarak nasıl çalıştığını gözlemlemeye dayalı “ablasyon” tekniği de kullanılıyordu. Lakin bu sistemler, modelin genel düşünme sürecini anlamak için yetersiz kalıyordu. Anthropic, bu sorunu aşmak için büsbütün yeni bir model geliştirdi: Cross-Layer Transcoder (CLT). CLT, yapay zeka modelini ferdi nöron düzeyinde değil, yorumlanabilir özellik kümeleri düzeyinde tahlil ediyor. Örneğin, muhakkak bir fiilin tüm çekimleri yahut “daha fazla” manasına gelen tüm tabirler tek bir özellik kümesi olarak ele alınabiliyor. Bu sayede, araştırmacılar modelin muhakkak bir misyonu yerine getirirken hangi nöron kümelerinin birlikte çalıştığını görebiliyor. Ayrıyeten, bu prosedür araştırmacılara hudut ağı katmanları boyunca modelin akıl yürütme sürecini takip etme imkanı sağlıyor.
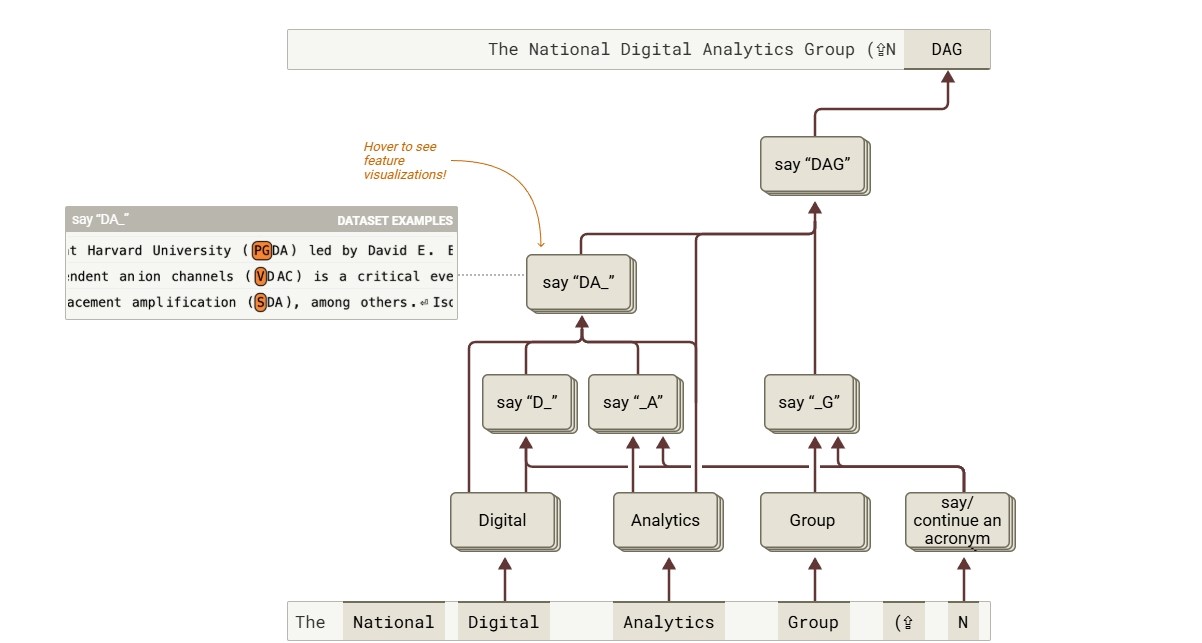 Lakin Anthropic, prosedürün bazı sınırlamaları olduğuna da dikkat çekti. Bu teknik, karmaşık bir modelin (örneğin Claude) içinde gerçekte neler olup bittiğinin sırf bir kestirimini sunuyor. Ayrıyeten, CLT prosedürünün tespit ettiği devreler dışında kalan ve modelin çıktılarında kritik bir rol oynayan kimi nöronlar gözden kaçabilir. Bunun yanında, büyük lisan modellerinin temel çalışma prensiplerinden biri olan “dikkat” sistemini da yakalayamıyor. Bu sistem, modelin girdi metnindeki farklı kısımlara farklı derecelerde ehemmiyet vermesini ve bu ehemmiyetin çıktı oluşturuldukça dinamik olarak değişmesini sağlar. CLT yolu, bu dikkat kaymalarını yakalayamıyor ve bu kaymalar, modelin “düşünme” sürecinde değerli bir rol oynayabilir.
Lakin Anthropic, prosedürün bazı sınırlamaları olduğuna da dikkat çekti. Bu teknik, karmaşık bir modelin (örneğin Claude) içinde gerçekte neler olup bittiğinin sırf bir kestirimini sunuyor. Ayrıyeten, CLT prosedürünün tespit ettiği devreler dışında kalan ve modelin çıktılarında kritik bir rol oynayan kimi nöronlar gözden kaçabilir. Bunun yanında, büyük lisan modellerinin temel çalışma prensiplerinden biri olan “dikkat” sistemini da yakalayamıyor. Bu sistem, modelin girdi metnindeki farklı kısımlara farklı derecelerde ehemmiyet vermesini ve bu ehemmiyetin çıktı oluşturuldukça dinamik olarak değişmesini sağlar. CLT yolu, bu dikkat kaymalarını yakalayamıyor ve bu kaymalar, modelin “düşünme” sürecinde değerli bir rol oynayabilir. Anthropic ayrıyeten, ağın devrelerini tahlil etmenin hayli vakit alıcı olduğunu vurguladı. Sırf “onlarca kelimeden” oluşan kısa girdiler için bile bir insan uzmanının birkaç saatini alabiliyor. Prosedürün çok daha uzun girdilere nasıl ölçeklenebileceği ise belirsizliğini koruyor. Lakin yeniden de CLT, Pandora’nın kutusunu açmak için atılmış son derece değerli bir adım.


